I learned about "Grundy's Game." This game is played by two players as follows:
1. The game starts with a single heap of objects.
2. The first player chooses a heap and splits the heap into two heaps of different sizes.
3. The second player does the same thing as 2.
4. Repeat 2. and 3. The player who cannot make a proper move loses.
For example, let's say the size of an initial heap is 9.
The first player splits a heap into (4, 5).
The second player splits the second heap into (2, 3), making the heap sizes (4, 2, 3).
The first player splits the first heap into (2, 2), making the heap sizes (2, 2, 2, 3).
The second player splits the last heap into (1, 2), which is the only allowed move here, making the heap sizes (2, 2, 2, 1, 2).
Now there are no proper moves available.
You cannot split a heap of the size 1.
And You cannot split a heap of the size 2 into two heaps
of different sizes.
Therefore the second players wins in the example.
Umm, sounds like a good way to kill time. You can play with some coins.
I wrote a program that returns the optimal strategy for this game. As you can guess from the name of this game, I used Grundy numbers. Just run the program, input the heap sizes, like, 10 or 5 10 20 or whatever. That's it.
#include <iostream>
#include <vector>
#include <set>
#include <sstream>
using namespace std;
const int MAX_V = 1000;
int g[MAX_V + 1];
void init() {
for (int i = 2; i <= MAX_V; i++) {
set<int> s;
for (int j = 1; 2 * j < i; j++) {
s.insert(g[j] ^ g[i-j]);
}
while (s.count(g[i]))
++g[i];
}
}
void solve(vector<int> &a) {
int sum = 0;
for (int i = 0; i < a.size(); i++)
sum ^= g[a[i]];
for (int i = 0; i < a.size(); i++) {
sum ^= g[a[i]];
for (int j = 1; 2 * j < a[i]; j++) {
if (!(sum ^ g[j] ^ g[a[i] - j])) {
for (int k = 0; k < a.size(); k++) {
if (k == i)
cout << j << " " << (a[i] - j) << " ";
else
cout << a[k] << " ";
}
cout << endl;
return;
}
}
sum ^= g[a[i]];
}
cout << "Uncle." << endl;
}
int main(int argc, char **argv) {
init();
for (string line; getline(cin, line), line != "bye"; ) {
istringstream iss(line);
vector<int> a;
int n;
while (iss >> n)
a.push_back(n);
solve(a);
}
return 0;
}



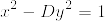
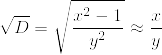
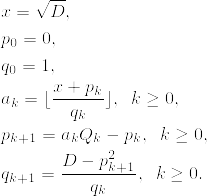
%20%3D%20%5Csum_%7Bd%20%7C%20n%7D%20%5Cmu(d)%20%5Cfrac%7Bn%7D%7Bd%7D.png)
.png)